Stock prediction using Azure Machine Learning
I like dabbling in the stock market, and wondered if artificial intelligence could help predict when I should buy/sell stock.
Using one of the FANG stocks (Facebook, Amazon, Netflix, Google) I'll choose Netflix for the purposes of this blog post.
Here is what Netflix has done in the last 3 months:
 The top graph is Fast Stochastics (12,26)
The top graph is Fast Stochastics (12,26)
As you can see, predicting the future is not easy.
So my first step was to not use AI at all, but to write a program to help me decide which values of %K and %D I should use for the Fast Stochastics graph, using the last 5 years of stock history for Netflix.
Change the Time period to 5Y and press Apply. Then click the download data link to obtain your CSV file.

The fee for buying/selling stock is £10 (Motley Fool), and Netflix shares incurr a currency fee of £49. So each Netflix trade would cost me £59 GBP.
I will use a £15000 as an example for my investment. Simply buying stock 5 years ago and selling it 5 years later, the money I would have is £219,342.80
The program I wrote iterates through %K values of 3 to 100, and for each value of %K, iterate %D values of 2 to 100, and for each value of %D, iterate a buy/sell trigger by looking at the difference between %K and %D from 1 to 100. 941094 iterations in all. Each buy/sell incurs fees, and each time we sell, it's below the value we could buy at.
So the target to beat is £219,342.80, and the top results are:
k: 4, d: 4, kdDiff 55, profit: £166,469.40 loss: -£8,350.28, gain: £174,819.70, money £180,997.40
k: 52, d: 40, kdDiff 42, profit: £161,173.20 loss: -£3,937.38, gain: £165,110.60, money £175,583.20
Here is what a fast stochastic (4,4) looks like:
 The difference between the %K (black line) and %D (Red line) must be 55 in order to trigger a buy/sell.
The difference between the %K (black line) and %D (Red line) must be 55 in order to trigger a buy/sell.
The 2nd best graph looks like:
 The difference between the %K (black line) and %D (Red line) must be 42 in order to trigger a buy/sell.
The difference between the %K (black line) and %D (Red line) must be 42 in order to trigger a buy/sell.
First off, we need the historical data, along with the correct buy/sell flag depending on what tomorrow brings. This is easy to work out as looking back in time is easy.
Using SQL Server, I imported the historical data into a table. I did this by using SSMS and right clicking on the database --> Tasks --> Import Data. Select the NFLX.csv file as the source, and the destination as "sql server native client". Press next a few times and finish. And voila, data is now in a table called NFLX. I left everything as string data, which is fine for my import.
Create a table with:
Feel free to import any other data you wish into separate tables. Hence the need for the name discriminator.
The insert is as follows:
Next, we need to correctly set the buy column by looking at the next days close. That should tell us if would should buy or sell. This is done via:
Ok, so now we historical data, and we have a buy/sell flag that I'd like the AI to try and learn to forecast.
Let's export this data into a CSV file.
Run this:
Right click on the results and select "Save results as". I chose StockPrediction.csv on the desktop.
Edit the file and add in the header row: id,name,date,open,high,low,close,adj_close,volume,buy
Fire up your Azure portal and create yourself a Machine learning studio. Once that has been created, head over to Microsoft Azure Machine Learning Studio.
Import your dataset by clicking on "Datasets", and clicking +New icon.

I won't bore you with all the steps, and jump straight to it. Create an experiment, and drop in your StockPrediction.csv file.

Because I have several sets of stock data in the csv file, I only want netflix data. So in the "Apply SQL Transformation" I have
For Split Data I have 0.95, meaning I want it to predict the final 5% of data, which is 2 months worth of data to predict. This is usually set to 0.7 for most models, so the last 30% is predicted. Predicting 2 months in advance is plenty for me, so I'm going with 0.95.
For Train Models, select the column 'buy'. This is what we want to predict.
I am using 2 AI engines, to compete against each other, to see which is best for this particular problem. At the botton, click the Run button. Once complete, right click on the "Evaluate Model", and select Evaluation results --> Visualise.
ROC
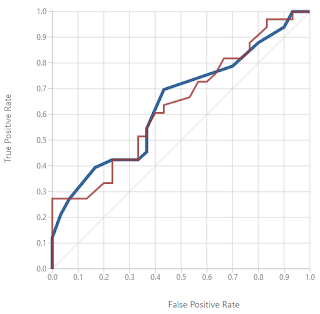 The results are better than guessing as they are over the midway line. The best graph to see is one that goes straight up the left hand side to the top, then across the top to the top right.
The results are better than guessing as they are over the midway line. The best graph to see is one that goes straight up the left hand side to the top, then across the top to the top right.
Precision/Recall
 As you can see, it's about 50% accurate.
As you can see, it's about 50% accurate.
Trying with the "Two-Class Neural Network", and a few tweaked values for the AI settings, I get the following results:


It was a good experiment, and one I will keep playing with. It made me realise that more data, perhaps even extraneous data, is also required to help train the AI's to give better predictions.
Using one of the FANG stocks (Facebook, Amazon, Netflix, Google) I'll choose Netflix for the purposes of this blog post.
Here is what Netflix has done in the last 3 months:

As you can see, predicting the future is not easy.
So my first step was to not use AI at all, but to write a program to help me decide which values of %K and %D I should use for the Fast Stochastics graph, using the last 5 years of stock history for Netflix.
Historical data
This can be obtained from Yahoo finance.Change the Time period to 5Y and press Apply. Then click the download data link to obtain your CSV file.

Best %K %D Fast Stochastics values for Netflix
The program I wrote takes into account that buying stock and selling stock incur a fee, and that the buy and sell values are not the same (bid/ask difference).The fee for buying/selling stock is £10 (Motley Fool), and Netflix shares incurr a currency fee of £49. So each Netflix trade would cost me £59 GBP.
I will use a £15000 as an example for my investment. Simply buying stock 5 years ago and selling it 5 years later, the money I would have is £219,342.80
The program I wrote iterates through %K values of 3 to 100, and for each value of %K, iterate %D values of 2 to 100, and for each value of %D, iterate a buy/sell trigger by looking at the difference between %K and %D from 1 to 100. 941094 iterations in all. Each buy/sell incurs fees, and each time we sell, it's below the value we could buy at.
So the target to beat is £219,342.80, and the top results are:
k: 4, d: 4, kdDiff 55, profit: £166,469.40 loss: -£8,350.28, gain: £174,819.70, money £180,997.40
k: 52, d: 40, kdDiff 42, profit: £161,173.20 loss: -£3,937.38, gain: £165,110.60, money £175,583.20
Here is what a fast stochastic (4,4) looks like:
The 2nd best graph looks like:
Azure Machine Learning and AI
First off, we need the historical data, along with the correct buy/sell flag depending on what tomorrow brings. This is easy to work out as looking back in time is easy.
Using SQL Server, I imported the historical data into a table. I did this by using SSMS and right clicking on the database --> Tasks --> Import Data. Select the NFLX.csv file as the source, and the destination as "sql server native client". Press next a few times and finish. And voila, data is now in a table called NFLX. I left everything as string data, which is fine for my import.
Create a table with:
CREATE TABLE StockPrediction ( id INT IDENTITY(1,1) NOT NULL PRIMARY key, [name] VARCHAR(50) NOT NULL, [date] DATETIME NOT NULL, [open] DECIMAL(10,4) NOT NULL, [high] DECIMAL(10,4) NOT NULL, [low] DECIMAL(10,4) NOT NULL, [close] DECIMAL(10,4) NOT NULL, adj_close DECIMAL(10,4) NOT NULL, volume int NOT NULL, buy BIT null )
Feel free to import any other data you wish into separate tables. Hence the need for the name discriminator.
The insert is as follows:
INSERT INTO StockPrediction (name,date,[open],high,low,[close],adj_close,volume) SELECT 'NFLX',[Date],[Open], High, Low, [Close], [Adj Close], Volume FROM nflx UNION ALL SELECT 'PPH',[Date],[Open], High, Low, [Close], [Adj Close], Volume FROM PPH
Next, we need to correctly set the buy column by looking at the next days close. That should tell us if would should buy or sell. This is done via:
UPDATE StockPrediction SET buy = CASE WHEN (future.[close] > StockPrediction.[close]) THEN 1 ELSE 0 END FROM StockPrediction JOIN StockPrediction future ON future.id = StockPrediction.id + 1; UPDATE StockPrediction SET buy = 0 WHERE buy IS NULL;
Ok, so now we historical data, and we have a buy/sell flag that I'd like the AI to try and learn to forecast.
Let's export this data into a CSV file.
Run this:
SELECT * FROM StockPrediction
Right click on the results and select "Save results as". I chose StockPrediction.csv on the desktop.
Edit the file and add in the header row: id,name,date,open,high,low,close,adj_close,volume,buy
Fire up your Azure portal and create yourself a Machine learning studio. Once that has been created, head over to Microsoft Azure Machine Learning Studio.
Import your dataset by clicking on "Datasets", and clicking +New icon.

I won't bore you with all the steps, and jump straight to it. Create an experiment, and drop in your StockPrediction.csv file.

Because I have several sets of stock data in the csv file, I only want netflix data. So in the "Apply SQL Transformation" I have
select * from t1 where name='NFLX' order by id;
For Split Data I have 0.95, meaning I want it to predict the final 5% of data, which is 2 months worth of data to predict. This is usually set to 0.7 for most models, so the last 30% is predicted. Predicting 2 months in advance is plenty for me, so I'm going with 0.95.
For Train Models, select the column 'buy'. This is what we want to predict.
I am using 2 AI engines, to compete against each other, to see which is best for this particular problem. At the botton, click the Run button. Once complete, right click on the "Evaluate Model", and select Evaluation results --> Visualise.
ROC

Precision/Recall

Trying with the "Two-Class Neural Network", and a few tweaked values for the AI settings, I get the following results:


Summary
Given the 5 year history of Netflix stock data, on a day by day basis is not good enough for the AI to accurately predict with. However, it's not bad. More fine grained data (per minute), and many more columns are required to help train it even better. The extra columns could be how many times Netflix appears in a tweets on that day (and the gauge of the sentiment), did directors buy/sell shares, and if so, how many, etc, etc. The more, the better. It doesn't matter if YOU think it's not relevant as the AI training will work out what data works best. Always remove the human bias, as shown by the Google chess/go playing AI proved as it beat the human biased AI every timeIt was a good experiment, and one I will keep playing with. It made me realise that more data, perhaps even extraneous data, is also required to help train the AI's to give better predictions.

